Az NTFS 5
filerendszerről
Nyelvtanfolyamokon gyakori feladat, hogy
meséljük el, mit vinnénk magunkkal egy lakatlan szigetre. Ez jó
szókincsfejlesztő gyakorlat – balta, fűrész, facsavar és más érdekes szavak kerülnek
ilyenkor elő. Egy vérbeli informatikus viszont szerintem nem bajlódik ilyen
gyerekségekkel, és amikor a válaszadásban rá kerül a sor, két szót – mint egy
mantrát, ld. még Hare Krisna -
mormol csupán: Peter Norton. Elvégre amire nincs Norton Utility, az nem
is igazi probléma, azzal nem is érdemes foglalkozni. Amikor a Norton Disk
Doctor (ndd) már legalább ötvenedjére mentette meg éppen elveszni készülő
file-jaimat egy-egy lemez megjavításával többször is arra gondoltam, Nortonnak
kellene operációs rendszert írnia és akkor mindenféle „más” operációs
rendszerek lelki nyavalyáit el is felejthetnénk. Milyen jól hangzana mondjuk
valami ilyesmi: Norton Linux, hm? Esetleg NortonBSD.
Aztán amikor NT-vel kezdtem dolgozni, a „Norton Istálló” szoftverei kezdek
kiszorulni az életemből – egyrészt mert a DOS-os verziók persze nem mentek
NT-n, másrészt meg amúgyis jóval ritkábban lett volna rájuk szükség. Ha már az
ndd került elő – a Microsoft rengeteg energiát fektetett abba, hogy egy valóban
stabil és megbízható filerendszerrel váltsa le a már réges – rég elavult
FAT-ot. A teljesítendő követelmények egyértelműek voltak:
- megbízhatóság:
egy-egy rendszerösszeomlás után a filerendszernek nem szabad összeomlania; ha adatok vesznek is el, legalább a
filerendszer – metaadatoknak épségben át kell vészelniük a crash-t.
- biztonság:
a filerendszernek biztosítania kell, hogy a file-okhoz csak az arra
jogosult felhasználók férhessenek hozzá.
- a drága
hardveres RAID rendszereket kiváltandó, szoftveres hibatűrő alrendszereket
is támogatnia kell.
Az első követelményt az NTFS úgy teljesíti, hogy az I/O műveleteket, melyek
a filerendszer struktúráját megváltoztatják (pl. új könyvtár, file létrehozása,
stb) atomi tranzakcióként kezeli, így aztán egy esetleges áramszünet után a
félbemaradt filerendszeműveletek visszagörgethetők. Ettől persze az érintett
file-ok tartalma még elveszhet, de legalább maga a filerendszer konzisztens
állapotban marad. Ezenkívül a kritikus rendszerinformációkat duplán tárolja a
filerendszer, így ha egy fontos szektor megsérül nem omlik össze a világegyetem
– és Norton mester tovább pihenhet.
A biztonság külön történet. Mindenki tudja, hogy egy-egy file-hoz a
hozzáférési jogok egy, a file-hoz csatolt DACL listában tárolódnak, és néhányan
még azt is tudják, hogy ez így, ebben a formában immár nem pontosan igaz – de,
ahogy a mese mondja, ez már egy másik történet, és majd később mesélek róla. A
szoftveres RAID megoldások (lemeztükrözés és paritásos csíkkészlet) A Windows 2000-ben némileg megújultak a Veritas dinamikus
lemezkezelési megoldása integrálásának köszönhetően – erről viszont az előző
írásom szól, mely A Windows 2000 lemezkezelésének újdonságai címet viseli. Igen, a leggyorsabban úgy
lehet cikket írni, ha az ember semmi mást nem csinál, mint már megjelent vagy
még meg sem jelent –sőt az igazi profi soha meg sem jelenő - írásokra
hivatkozik. Rövid és nem túl gyümölcsöző tudományos pályafutásom alatt ezt
mindenesetre sikerült megtanulnom.
Amiről viszont most ténylegesen szeretnék írni, az az NTFS 5 belső struktúrája.
Ezen struktúra legnagyobb egysége a volume, azaz kötet, ami a legtöbb esetben
megfelel egy partíciónak, amit NTFS-re formázunk (cf. A Windows 2000 lemezkezelésének újdonságai). A volume-on a file-ok adott méretű
egységekben, ún. clusterekben tárolódnak. Maguknak a clustereknek a mérete
változó lehet, de mindig egész számú többszöröse a szektorméretnek (általában
négyzetes hatványa), ez utóbbi viszont az Intel – univerzumban 512 byte. Csak
hogy egyszerűbb legyen a kép, a cluster méretet általában nem szektorban, hanem
byte-ban adják meg, így azután a szektort mint mértékegységet el is lehet
felejteni. Maga az NTFS is clusterekkel dolgozik, bár van néhány alacsony
szintű I/O művelet, ami szektorszinten zajlik. A clustereket a filerendszer
sorszámok szeint tartja nyilván; ezeket a sorszámokat
logikai clusterszámoknak (Logical Cluster Numbers, LCN) nevezzük. Ha a rendszer
arra kíváncsi, hogy egy adott cluster fizikailag hol helyezkedik el a köteten,
egyszerűen csak meg kell szoroznia az LCN-t a szektortényezővel (vagyis hogy
hány 512 byte-os szektor alkot egy clustert), és máris megvan a kívánt
információ.
Egy adott file a köteten egy vagy több fizikai clustert foglalhat el. Az
NTFS külön számozza az adott file által használt clustereket is, ezeknek virtuális
clusterszámot (Virtual Cluster Number, VCN) ad. A VCN és az LCN egymástól
függetlenek; tulajdonképpen a filerendszer
legfontosabb feladata, hogy minden egyes file-ra nyilvántartson közöttük egy
leképezést – vagyis hogy az adott file különböző darabkái, melyek a VCN által
sorszámozódnak, vajon milyen fizikai lemezterületeken (LCN-nel nyilvántartott
clustereken) vannak szétszórva. Jó esetben, ha a kötet nem töredezett, vagyis
fragmentált, egy adott file a
köteten folytonosan helyezkedik el – ilyenkor a nyilvántartás könnyű, mert csak
azt kell „észben tartani”, hogy egy adott file mely clusteren kezdődik és hogy
mekkora. Kevésbé jó esetben, amikor a kötet töredezett – és a valós világhoz
azért sajnos ez a példa áll közelebb – ennél sokkal bonyolultabb a kép, hisz
egy file-nak akár minden darabkája különféle helyeken levő clusterekbe lehet
szétszórva. Akár így, akár úgy, a nyilvántartást vezetni kell; az NTFS erre a feladatra Master File Table (MFT) néven tart fenn
egy táblázatot, mely – igazodván az NTFS alapfilozófiájához – maga is egy
(rejtett) file, ami a köteten tárolódik, méghozzá két példányban a jobb
hibatűrés érdekében. Az MFT-ben az egyes rekordok (melyeknek mérete mindig 1Kb)
egy-egy file különféle adatait tartalmazzák, sőt, ha a elég kicsi, maga a file
is itt tárolódik.
Amikor a Windows 2000 elindul, adott pillanatban felmountolja
az általa kezelt filerendszereket. Ez – sokminden más mellett persze – azt
jelenti, hogy az NTFS filerendszer a boot szektorból kikeresi az MFT fizikai
helyét a lemezen. Az MFT első rekordja saját magáról szól (ld. még: „Az állam
én vagyok”), a második pedig az ő másodpéldányáról, ami a lemez közepén
helyezkedik el. Az MFT következő tízegynéhány rekordja további filerendszer
metafile-okról ad információt; a felhasználói
file-ok nyilvántartása csak a 16. számú rekorddal kezdődik. Ezek a metafile-ok
szükségesek a kötet inicializálásához, ezért kell tehát őket a mount művelet
alatt a filerendszer drivernek elérnie. Maguk a metafile-ok is megérnének egy
külön cikket, de mivel most a filerendszer felépítéséről van szó és ebből a
szempontból ők is közönséges file rekordokként kezelődnek, lépjünk túl rajtuk.
A file-okat az NTFS köteten egy 64 bites szám azonosítja, az ún. file
referencia (file reference). Ebből 48 bit a file sorszáma, ami azt mondja meg,
hogy az MFT-ben a rá vonatkozó rekord hol helyezkedik el (magyarul hányadik
rekord azonosítja az adott file-ot), a maradék 16 bit pedig, amit egyszerűen
sorszámnak (sequence number) neveznek, az NTFS számára belső konzisztenciaellenőrzési
célokat szolgál. Egy-egy MFT rekord sokféle attribútumot tartalmazhat, némelyik
kötelező, mások pedig felhasználói tevékenység hatására jönnek létre. Az előbb
említettem, hogy ha a file elég kicsi, akár ő maga is meghúzhatja magát a hozzá
tartozó MFT bejegyzésben. Ilyenkor maga a file tartalma is egy attribútumként
tárolódik, melynek neve – micsoda fantáziadús elnevezés – unnamed data
attribute. A lehetséges attribútumok teljes listája a következő:
|
Attribútum
|
Attribútum neve
|
Leírás
|
|
Volume Information
|
$VOLUME_INFORMATION, $VOLUME_NAME
|
Ezek az
attribútumok csak a $Volume
metafile-hoz tartoznak és a
kötet verziószámát és címke (label) információját tartalmazzák.
|
|
Standard Information
|
$STANDARD_INFORMATION
|
A klasszikus
file attribútumok (read-only, archive, stb), időbélyegek, valamint hogy hány
db hard link mutat a file-ra.
|
|
Filename
|
$FILE_NAME
|
Passz, fogalmam
sincs.
|
|
Security Descriptor
|
$SECURITY_DESCRIPTOR
|
A file-hoz tartozó
hozzáférési listák tárolódnak itt. Ez csak kompatibilitási okokból létezik
már; a Windows 2000 nem ez alapján dolgozik, hanem a $Secure metafile-ot használja. Erről bővebben majd egy következő cikkben.
|
|
Data
|
$DATA
|
A file tartalma
tárolódhat itt. Az NTFS több Data attribútumot is tárolhat egy file-hoz; alapértelmezésben ezekből 1 db
van, az Unnamed Data Attribute nevű. Ez érdekes dolgokat eredményezhet, még
visszatérünk rá.
|
|
Index root, Index Allocation, Index bitmap
|
$INDEX_ROOT,
$INDEX_ALLOCATION, $BITMAP
|
Ezek az
attribútumok csak könyvtár – rekordokhoz tárolódnak és az indexálást segítik.
|
|
Attribute list
|
$ATTRIBUTE_LIST
|
A file adatattribútumainak
felsorolása, valamint hogy ezek mely MFT rekordokban találhatóak.Ez az attribútum
ritkán használt; csak akkor van rá szükség, ha az adott
file leírása nem fér el egy db MFT rekordban.
|
|
Object ID
|
$OBJECT_ID
|
Egy 64 byte-os
azonosító, mely file-okhoz és könyvtárakhoz rendelhető (tudom, az előbb volt
szó egy 64 bitesről is, de ez most más tészta). Főleg a Dsitributed Link
Tracking Service használja, de – mivel az NTFS nem publikus, natív API-kat
szolgáltat hozzá – mezei programozónak csak elvileg lehetséges egy file vagy
könyvtár megnyitása Object ID, nem pedig név alapján is. Talán nem kell
mondanom, hogy néhány izgalmas rendszerkomponens azért él a lehetőséggel...
|
|
Reparse information
|
$REPARSE_POINT
|
Mount pontok és
Junction információk (=soft link) tárolódnak itt.
|
|
Extended attributes
|
$EA,
$EA_INFORMATION
|
Ezek az
attribútumok - hihetetlen, de
igaz – OS/2 kompatibilitási célt szolgálnak. Ennek megfelelően jobbára semmi
szükség rájuk.
|
|
EFS information
|
$LOGGED_UTILITY_STREAM
|
Ha egy file-ot
titkosítunk, a titkosítókulcsok itt tárolódnak.
|
No, ez egy kicsit töményre sikeredett; tanfolyamon ilyenkor szoktunk kávészünetet elrendelni, esetleg előkerül
egy aktuális poén is, de ez itt most egy komoly cikk, úgyhogy csak a szerző áll
fel és dönt le egy üveg barnasört. Az olvasó úgyis akkor száll ki, amikor neki
jólesik, bár ha eddig bírta, mostmár érdemes maradni szerintem.
...sör megvolt, pont a megfelelő hőmérsékletre hűtve, akár mehetünk is
tovább. Az előbbi táblázatban szereplő attribútumok egy része alapinformáció, esetleg
kötetszintű elemekkel (pl. Object ID), mások viszont az adott file-hoz (vagy
könyvtárhoz) tartozó egyedi jellemzők (pl. filenév). Mindezek alapján első
megközelítésben egy MFT rekord így néz ki:
| |
|
 |
A rekord minden darabkája (vagyis az előbbi táblázatban szereplú
attribútumok) egy – egy fejléccel (header) kezdődik, amit maga az attribútum
követ – már ha belefér az MFT rekordban számára fenntartott helybe
(emlékezzünk, egy MFT rekord 1kb méretű). Ebben az esetben rezidens
attribútumnak nevezzük az illetőt. Ha nem fér ide teljesen az attribútum, akkor
a neve nemrezidens (nahát), és ilyenkor a kilógó részek további MFT rekordokat
foglalhatnak el; természetesen ezt az MFT gondosan
nyilvántartja. A standard információkat és a fileneveket leszámítva minden
egyéb attribútum lehet nemrezidens, ha úgy hozza a rossz sorsa. Leggyakrabban
nyilván maga az adatrész (a file tényleges tartalma) nem fog beleférni a
rekordba, ilyenkor ennek az attribútumnak a szerepe megváltozik, és az adott
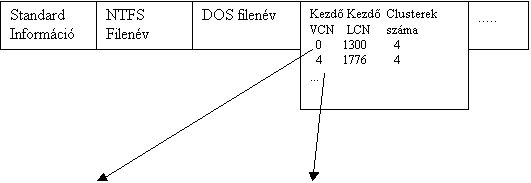
file VCN – LCN leképezését fogja nyilvántartani valahogy úgy, ahogyan az a következő ábrán látszik:
VCN: 0
1
2 3 VCN: 4 5 6 7
LCN: 1300 1301 1302 1303 LCN: 1776 1777
1778 1779
Az ábrán látható MFT rekord egy olyan file-hoz tartozik, mely a lemezen
összesen nyolc clusternyi helyet foglal el, a fragmentáció miatt sajnos nem
folytonosan, hanem két darabra osztva. A két filedarabkát az NTFS terminólógia
a file két futás-ának (run) nevezi. Ha a file nagyon nagy, a hozzá
tartozó VCN – LCN leképezés nyilvántartása nem fér már el egy MFT bejegyzésben; ilyenkor újabb rekordok szükségesek, hogy az imár
nemrezidens adat (data) attribútumot tárolni tudjuk.
A könyvtárakhoz tartozó MFT rekordok nagyjából úgyanúgy néznek ki, mint a
file – bejegyzések, esetükben viszont a főszerepet az Index Root attribútum és
társai kapják, melyekben az adott könyvtárban található file-ok rendezett
listája található, legalábbis addig, amíg a lista idefér. Ha túl sok file van a
listában, akkor a filenevek (a file-ok run-jaihoz hasonló) 4kb-os ún. Index
Bufferekben kerülnek felsorolásra oly módon, hogy ezekben a bufferekben a
filenevek b+
fa algoritmus alapján rendezettek, ily módon megkönnyítve az indexálást, illetve
minimalizálva a lemezműveletek számát egy – egy fileműveletkor.
Az NTFS belső felépítése
sokat változott az NT 4-ben megismert NTFS 3-hoz képest (4-es verzió
ebből nem volt), megjelent néhány új MFT attribútum, és a filerendszer metafile-ok
köre is bővült; ezen változások közül a legfontosabb talán a konszolidált
security descriptorok
bevezetése volt. E cikk folytatásában erről,
és általában az NTFS metafile-okról írok majd.
Farkas Zoltán MCSE, MCT
zoltan.farkas@wsh.hu
Felhasznált irodalom:
- D.Solomon,
M.Russinovich: Inside Windows 2000.
- H.Custer:
Inside NTFS FileSystem
- Windows
2000 Server Resource Kit
Forrás :